Blog
-
Towards General-Purpose In-Context Learning Agents
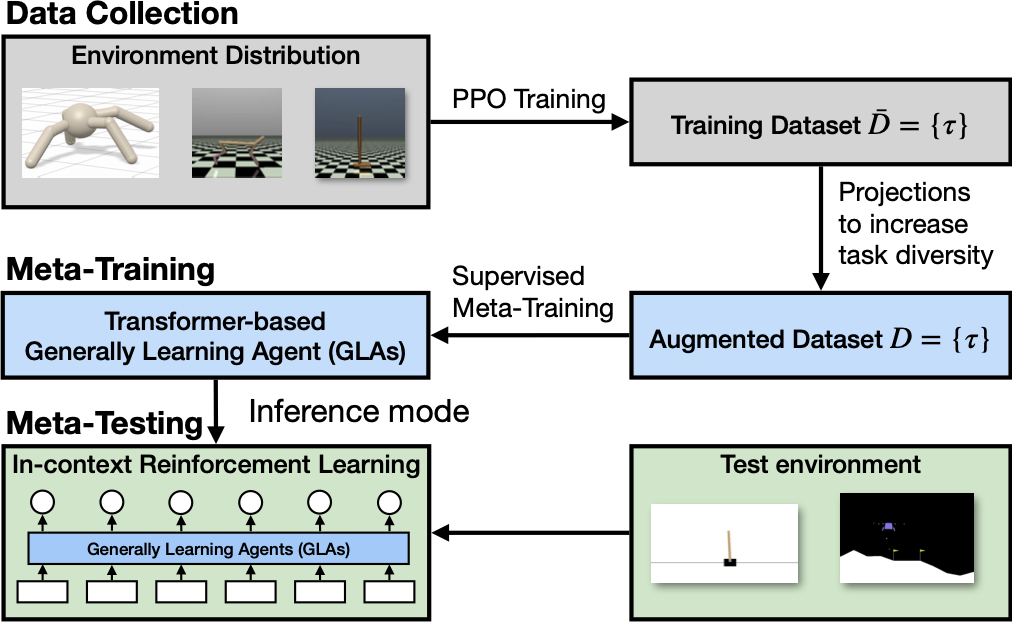
We meta-train in-context learning RL agents that generalize across domains (with different actuators, observations, dynamics, and dimensionalities) using supervised learning. [Continue reading]
-
General-Purpose In-Context Learning
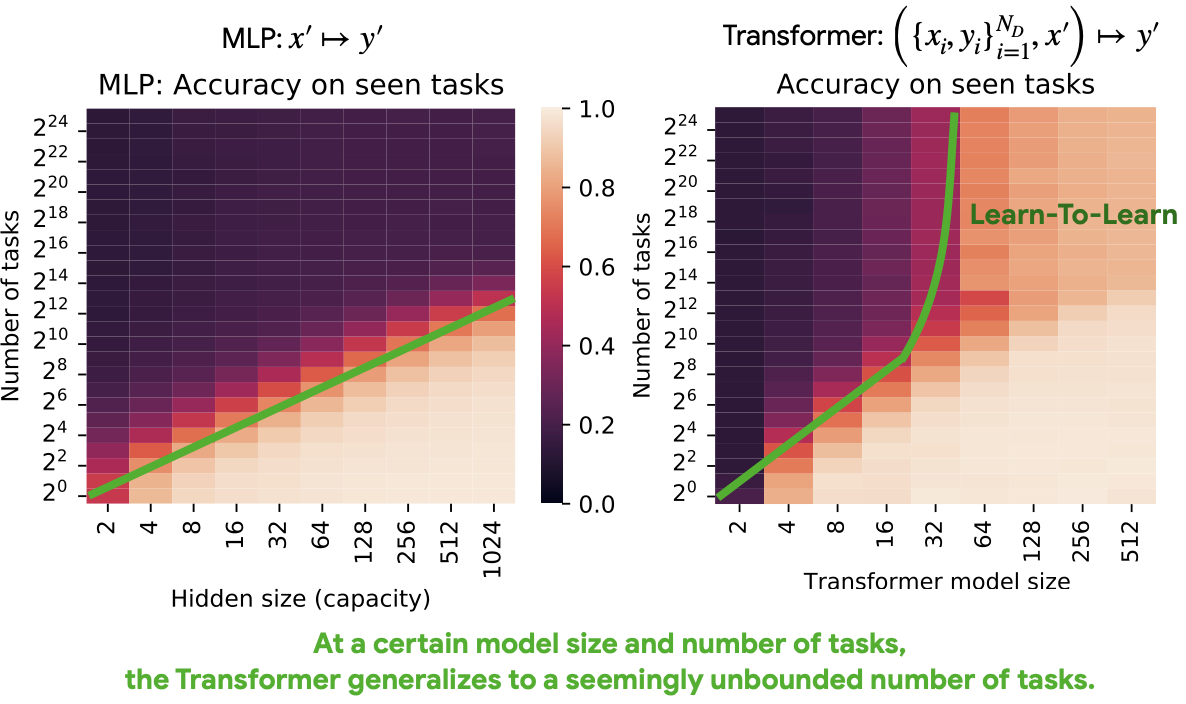
Transformers and other black-box models can exhibit in-context learning-to-learn that generalizes to significantly different datasets while undergoing multiple phase transitions in terms of their learning behavior. [Continue reading]
-
Self-Referential Meta Learning
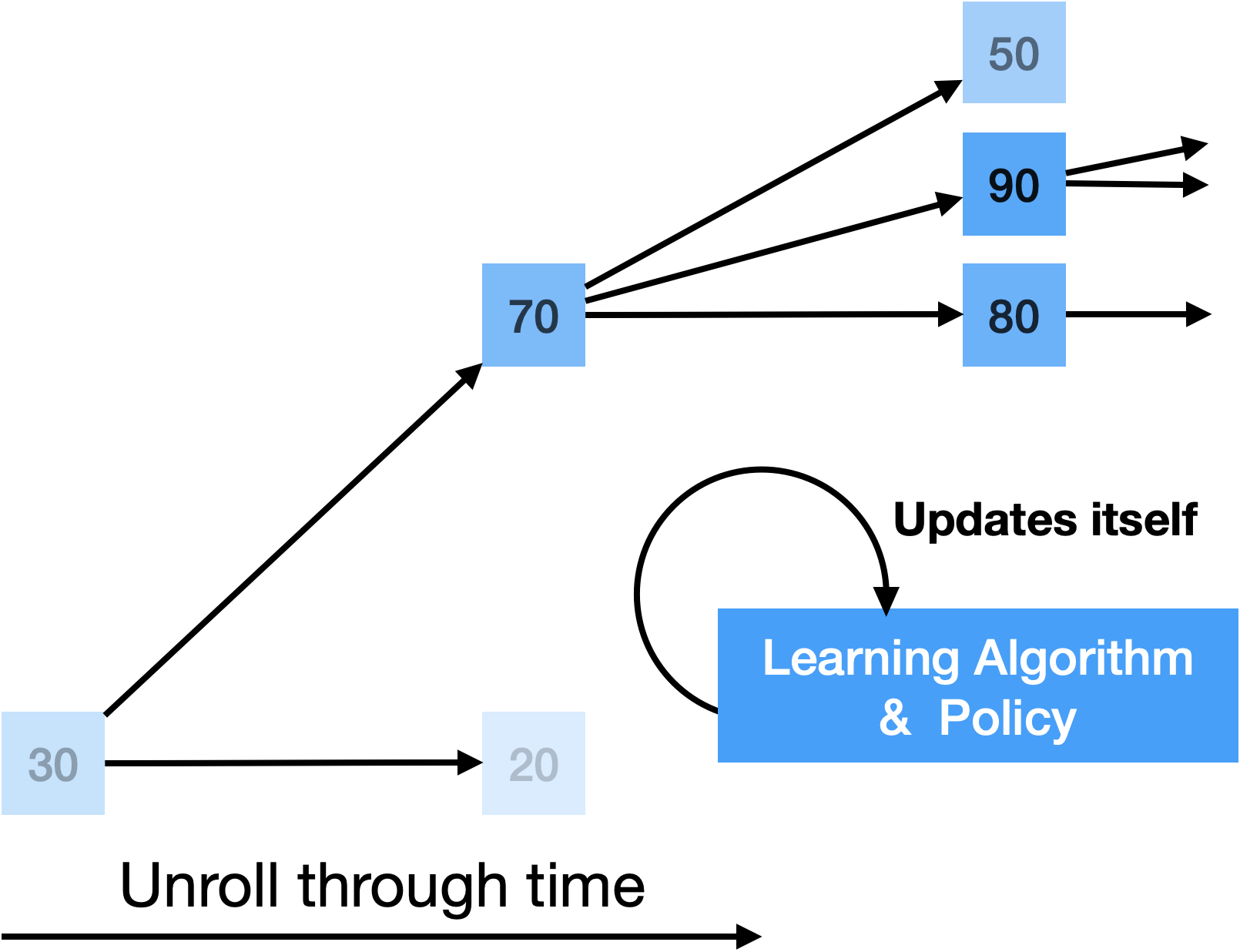
We investigate self-referential meta learning systems that modify themselves without the need for explicit meta optimization. [Continue reading]
-
Introducing Symmetries to Black Box Meta Reinforcement Learning
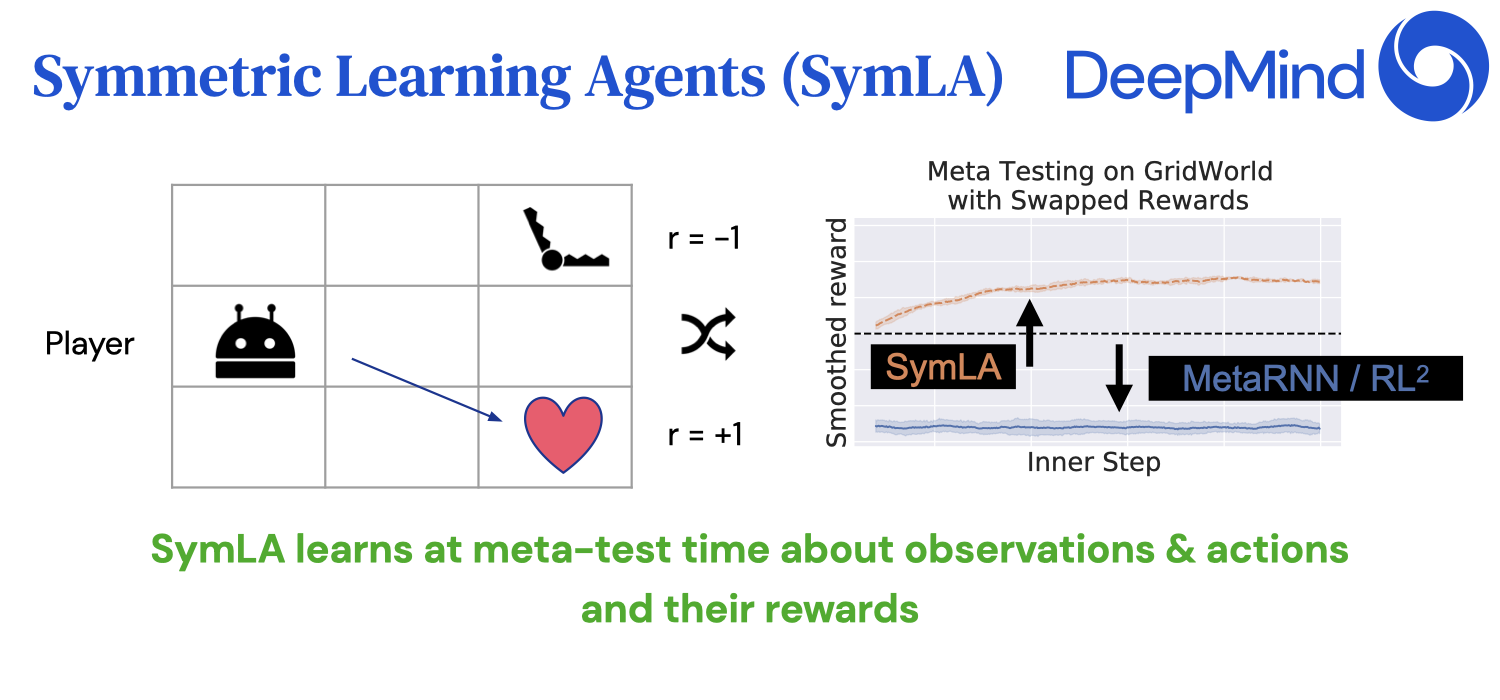
We add symmetries (permutation invariance) to black-box meta reinforcement learners to increase their generalization capabilities. [Continue reading]
-
Meta learning gradient-free learning algorithms
This year's NeurIPS 2021 I present one full paper and a workshop paper on meta learning gradient-free & general-purpose learning algorithms. Can the backpropagation algorithm be encoded purely in the recurrent dynamics of RNNs? How do we automatically discover novel general-purpose learning algorithms that do not need gradient descent? How can symmetries help generalization of reinforcement learning algorithms? [Continue reading]
-
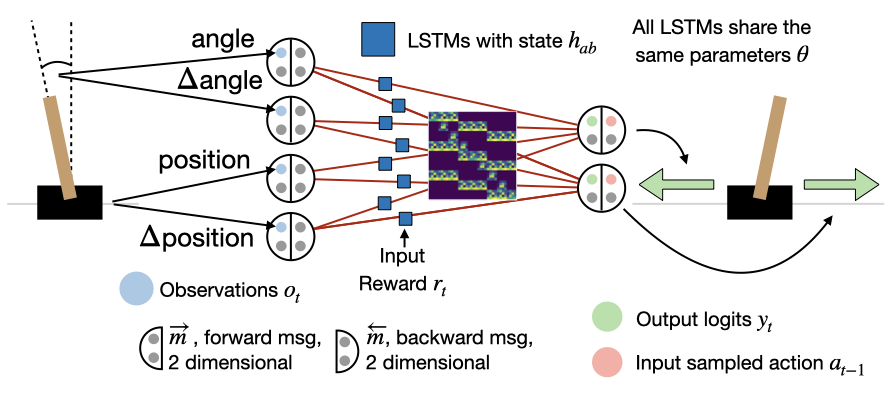
General Meta Learning and Variable Sharing
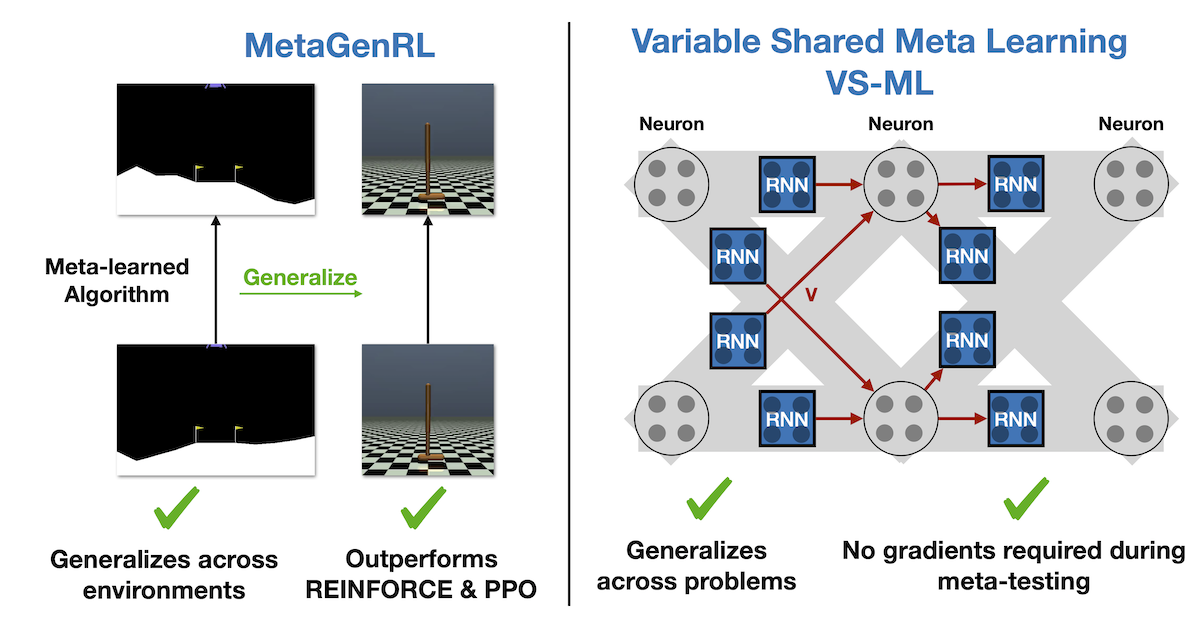
Humans develop learning algorithms that are incredibly general and can be applied across a wide range of tasks. Unfortunately, this process is often tedious trial and error with numerous possibilities for suboptimal choices. General Meta Learning seeks to automate many of these choices, generating new learning algorithms automatically. Different from contemporary Meta Learning, where the generalization ability has been limited, these learning algorithms ought to be general-purpose. This allows us to leverage data at scale for learning algorithm design that is difficult for humans to consider. I present a General Meta Learner, MetaGenRL, that meta-learns novel Reinforcement Learning algorithms that can be applied to significantly different environments. We further investigate how we can reduce inductive biases and simplify Meta Learning. Finally, I introduce Variable Shared Meta Learning (VS-ML), a novel principle that generalizes Learned Learning Rules, Fast Weights, and Meta RNNs (learning in activations). This enables (1) implementing backpropagation purely in the recurrent dynamics of an RNN and (2) meta-learning algorithms for supervised learning from scratch. [Continue reading]
-
MetaGenRL: Improving Generalization in Meta Reinforcement Learning
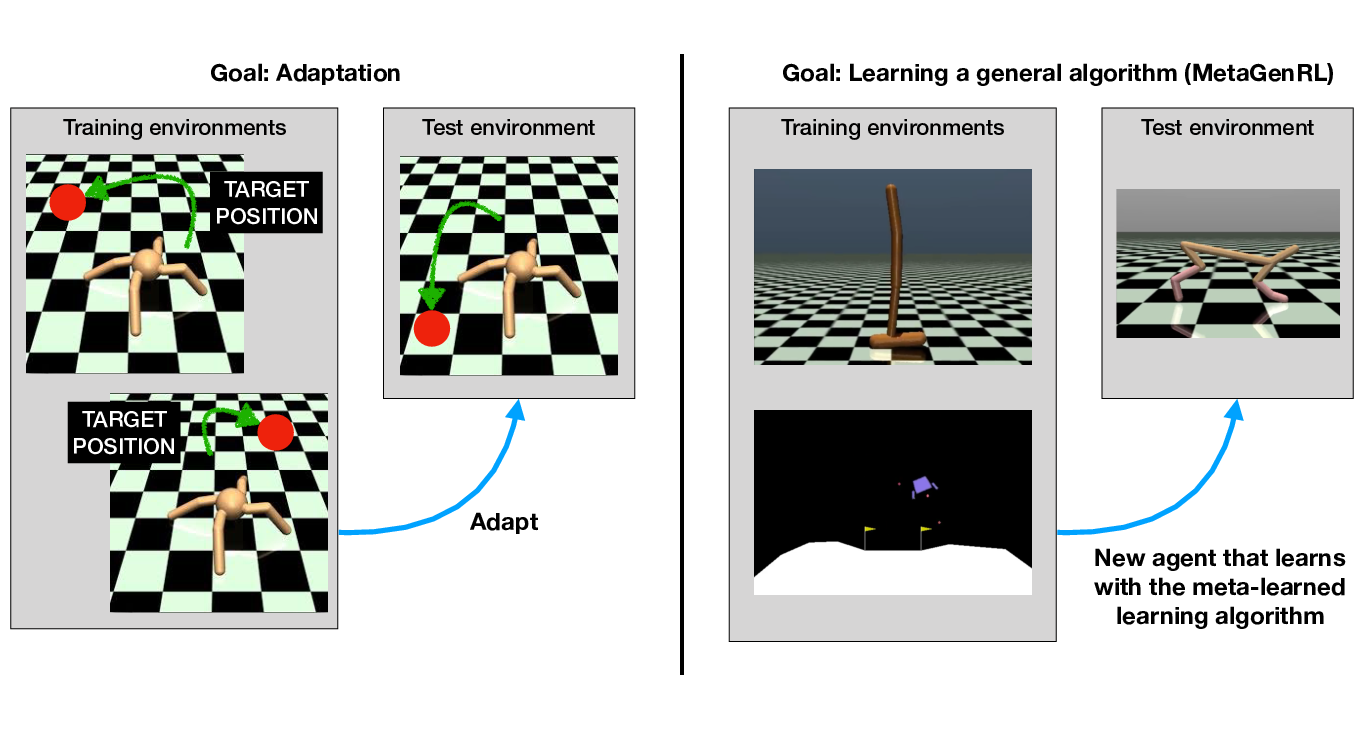
Biological evolution has distilled the experiences of many learners into the general learning algorithms of humans. Inspired by this process, MetaGenRL distills the experiences of many complex agents to meta-learn a low-complexity neural objective function that affects how future individuals will learn. Unlike recent meta-RL algorithms, MetaGenRL can generalize to new environments that are entirely different from those used for meta-training. In some cases, it even outperforms human-engineered RL algorithms. MetaGenRL uses off-policy second-order gradients during meta-training that greatly increase its sample efficiency. [Continue reading]
-
NeurIPS 2018, Updates on the AI road map
I present an updated roadmap to AGI with four critical challenges: Continual Learning, Meta-Learning, Environments, and Scalability. I motivate the respective areas and discuss how research from NeurIPS 2018 has advanced them and where we need to go next. [Continue reading]
-
A Map of Reinforcement Learning
Reinforcement Learning promises to solve the problem of designing intelligent agents in a formal but simple framework. This blog post aims at tackling the massive quantity of approaches and challenges in Reinforcement Learning, providing an overview of the different challenges researchers are working on and the methods they devised to solve these problems. [Continue reading]
-
How to make your ML research more impactful

We machine learning researchers all have a very limited amount of time to spend on reading research and there is only so few projects we can take on at a time. Thus, it is paramount to understand what areas of research excite you and hold promise for the future. I present my analysis of the factors of impactful ML research and how to increase your impact. [Continue reading]
-
Theories of Intelligence (2/2): Active Inference
We look at Active Inference, a theoretical formulation of perception and action from neuroscience that can explain many phenomena in the brain. It aims to explain the behavior of cells, organs, animals, humans, and entire species. This article is geared towards machine learning researchers familiar with probabilistic modeling and reinforcement learning. [Continue reading]
-
Theories of Intelligence (1/2): Universal AI

I give insight into a theoretic top-down approach of universal artificial intelligence. This may allow directing our future research by theoretical guidance, avoiding to handcraft properties of a system that may be learned by an intelligent agent. Furthermore, we will learn about theoretical limits of (non-)computable intelligence and introduce a universal measure of intelligence. [Continue reading]
-
Simple hyperparameter and architecture search in tensorflow with ray tune

In this blog post we want to look at the distributed computation framework ray and its little brother ray tune that allow distributed and easy to implement hyperparameter search. It not only supports population-based training, but also other hyperparameter search algorithms. Ray and ray tune support any autograd package, including tensorflow and PyTorch. [Continue reading]
-
Hyperparameter search with population based training in tensorflow
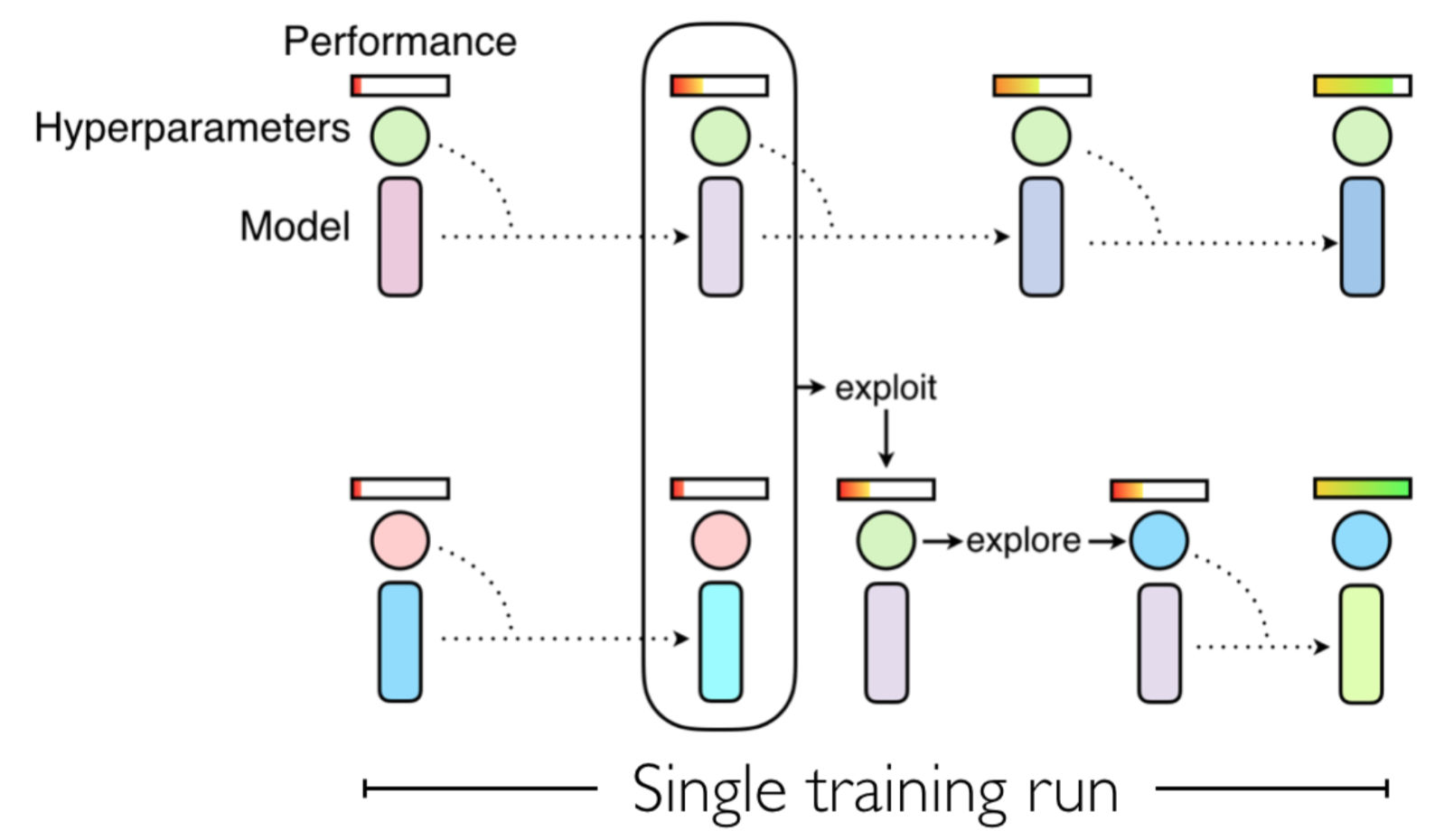
Deep learning researchers often spend a large amount of time tuning their architecture and hyper-parameters. A simple method to reduce this human effort is to perform a grid search, essentially random search, but requires exponential compute in the number of parameters. We will investigate a cheap and powerful alternative called population based training. [Continue reading]
-
Modular Networks: Learning to decompose neural computation
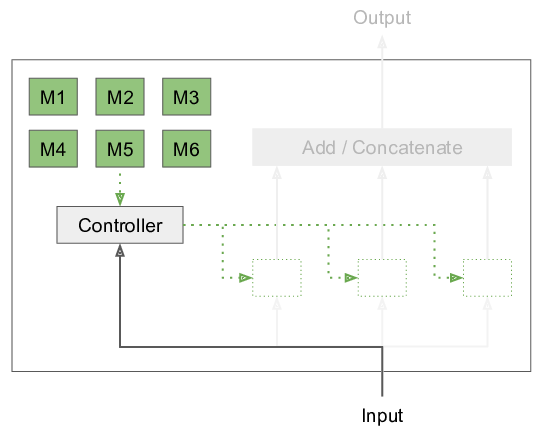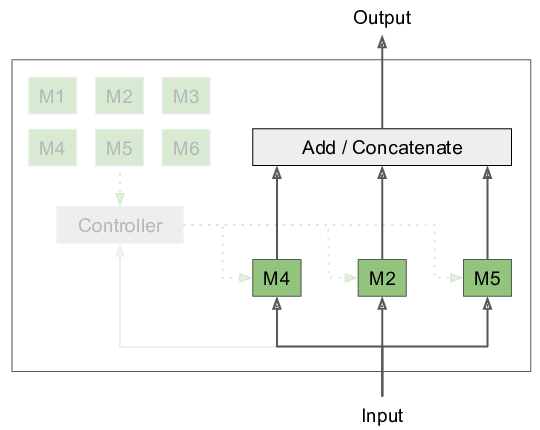
Currently, our largest neural networks have only billions of parameters, while the brain has trillions of synapses. To this date, we are not able to scale up artificial neural networks to trillions of parameters by performing the usual dense matrix multiplication. We introduce Modular Networks, a way to make neural networks modular, similar to what has been observed in the brain. In our approach, we execute only some of these modules, conditioned on the input to the network. Furthermore, we look at future possibilities of leveraging sparse computation. [Continue reading]
-
Why work on artificial intelligence?

This morning, you woke up and got out of bed. A human-made object that enables you to have an enjoyable and effective rest. You checked your smartphone, to communicate with the entire world instantly. You received all important news and notifications without any effort. Every day you use thousands of objects and processes that are human inventions, to make our lives more enjoyable and effective. Inventions, that enable us to truly focus on what's important. They free us from the requirement to dedicate our entire day to survival. Instead, we can focus on social, creative or inventive issues. Behind all this is only a single factor, human intelligence. [Continue reading]
subscribe via RSS
Follow @LouisKirschAI