MetaGenRL: Improving Generalization in Meta Reinforcement Learning
Biological evolution has distilled the experiences of many learners into the general learning algorithms of humans. Our novel meta reinforcement learning algorithm MetaGenRL is inspired by this process. MetaGenRL distills the experiences of many complex agents to meta-learn a low-complexity neural objective function that affects how future individuals will learn. Unlike recent meta-RL algorithms, MetaGenRL can generalize to new environments that are entirely different from those used for meta-training. In some cases, it even outperforms human-engineered RL algorithms. MetaGenRL uses off-policy second-order gradients during meta-training that greatly increase its sample efficiency.
Meta-Learning RL algorithms
Similar to many other researchers, my goal is to build intelligent general-purpose agents that can independently solve a wide range of problems and continuously improve. At the core of this ability are learning algorithms. Natural evolution for instance has equipped us humans with general learning algorithms that allow for quite intelligent behavior. These learning algorithms are the result of distilling the collective experiences of many learners throughout the course of evolution into a compact genetic code. In a sense, evolution is a learning algorithm that produced another learning algorithm. This process is called Meta-Learning and our new paper MetaGenRL for the first time shows that we can artificially learn quite general (albeit still simple) learning algorithms in a similar manner.
In contrast to this, most current Reinforcement Learning (RL) algorithms are the result of years of human engineering and design (such as REINFORCE, PPO, or DDPG). The problem with this approach is that we don’t know what the best learning algorithm is or which learning algorithm to use in which context. Thus, current algorithms are inherently limited by the ability of the researcher to make the right design choices. This problem is also discussed in Jeff Clune’s AI generating algorithms paper.
In Meta Reinforcement Learning we not only learn to act in the environment but also how to learn itself, reducing the beforementioned problem. This in principle allows us to meta-learn general learning algorithms that surpass human-engineered alternatives. Of course, we are not the first to suggest this, a good overview of Meta-RL can be found on Lilian Weng’s blog. Unfortunately, in practice, Meta Reinforcement Learning algorithms have focused on ‘adaptation’ to very similar RL tasks or environments until now. Thus, the learned algorithm would not be useful in a considerably different environment. For example, it would be unreasonable to expect that the algorithm could first learn to walk and then later learn to steer a car.
How MetaGenRL works
The goal of MetaGenRL is to meta-learn algorithms that generalize to entirely different environments. For this, we train RL agents in multiple environments (often called the environment or task distribution) and leverage their experience to learn an algorithm that allows learning in all of these (and new) environments.

This process consists of:
- Meta-Training: Improve the learning algorithm by using it in one or multiple environments and changing it such that it works better when an RL agent uses it to learn (increase reward income)
- Meta-Testing: Initialize a new RL agent from scratch, place it in a new environment, and use the learning algorithm that we meta-learned previously instead of a human-engineered alternative
When using a human-engineered algorithm we have no Meta-Training and only a testing phase:
- Testing: Initialize a new RL agent from scratch, place it in a new environment, and train it using a human-engineered learning algorithm
We represent our learning algorithm as an objective function \(L_\alpha\) that is parameterized by a neural network with parameters \(\alpha\). Many other human-engineered RL algorithms are also represented by a specifically designed objective function but in MetaGenRL we meta-learn instead of design it. When we minimize this objective function, the agent behavior improves to achieve higher rewards in an environment. In MetaGenRL, we leverage the experience of a population of agents to improve a single randomly initialized objective function. Each agent consists of a policy, a critic, and a replay buffer and acts in its own environment (schematic in the figure below). Let’s say we use 20 agents and two environments, then we would equally distribute the agents such that there are 10 agents in each environment.

During meta-training of the objective function, we will now:
- Have each agent interact with its environment and store this experience in its replay buffer
- Improve the critics using data from their replay buffers
- Improve the shared objective function that represents the learning algorithm using the current policies and critics.
- Improve the policy of each agent using the current objective function
- Repeat the process
Each step is done in parallel across all agents.
During meta-testing an agent is initialized from scratch and only the objective function is used for learning. The environment we test on can be different from the original environments we used for meta-training, i.e. our objective functions should generalize.
How does meta-training intuitively work? All agents interact with their environment according to their current policy. The collected experiences are stored in the replay buffer, essentially a history of everything that has happened. Using this replay buffer, one can train a separate neural network, the critic, that can estimate how good it would be to take a specific action in any given situation. MetaGenRL now uses the current objective function to change the policy (‘learning’). Then, this changed policy outputs an action for a given situation and the critic can tell how good this action is. Based on this information we can change the objective function to lead to better actions in the future when used as a learning algorithm (‘meta-learning’). This is done by using a second-order gradient, backpropagating through the critic and policy into the objective function parameters.

Sample efficiency and Generalization
MetaGenRL is off-policy and thus requires fewer environment interactions both for meta-training as well as test-time training. Unlike in evolution, there is no need to train multiple randomly initialized agents in their entirety to evaluate the objective function, thus speeding up the credit assignment. Rather, at any point in time, any information that is deemed useful for future environment interactions can be directly incorporated into the objective function by making use of the critic.
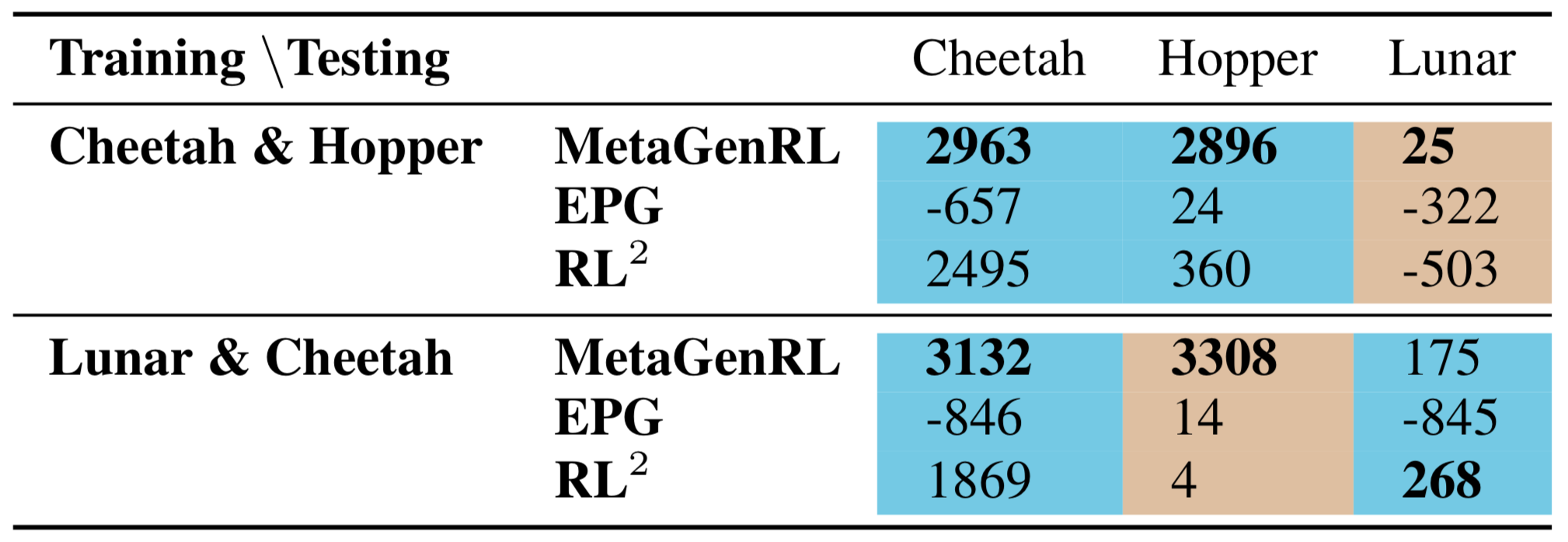
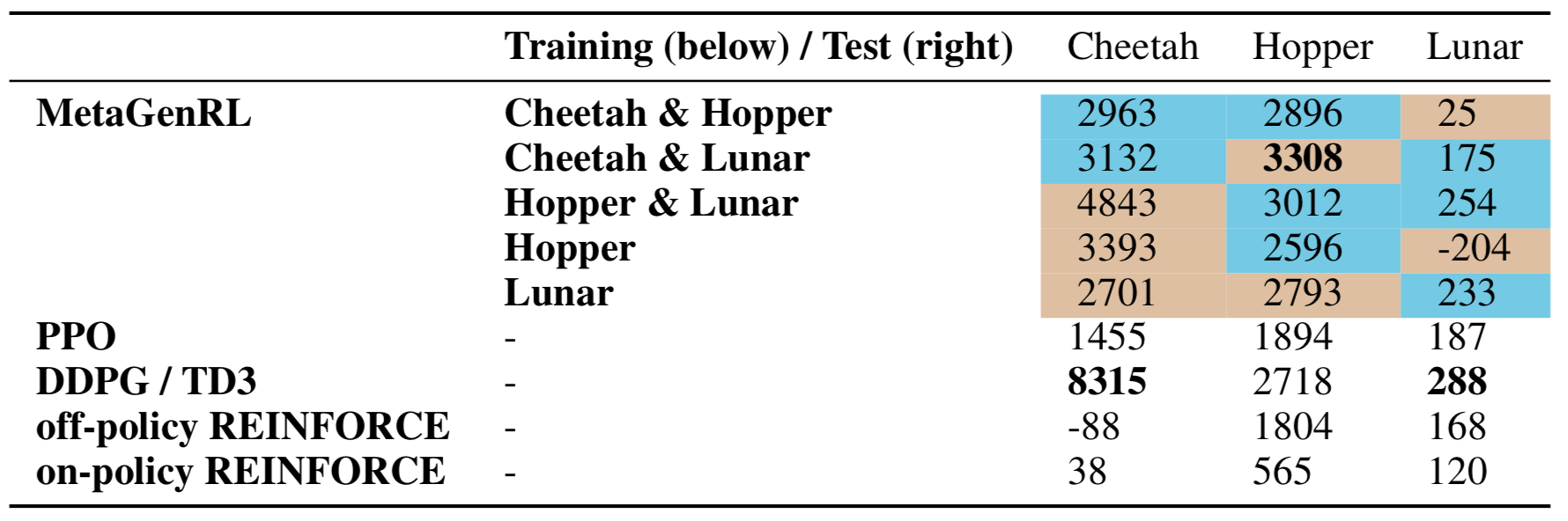
Furthermore, the learned objective functions generalize to entirely different environments. The figure below shows the test-time training (i.e. meta-testing) curve of agents being trained from scratch on the Hopper environment using the learned objective function. In general, we can outperform human-engineered algorithms such as PPO and REINFORCE, but sometimes still struggle against DDPG. Other Meta-RL baselines overfit to their training environments (see RL^2) or do not even produce stable learning algorithms when we allow for 50 million environment interactions (twice as many compared to MetaGenRL, see EPG).

Future work
In future work, we aim to further improve the learning capabilities of the meta-learned objective functions, including better leveraging knowledge from prior experiences. Indeed, in our current implementation, the objective function is unable to observe the environment or the hidden state of the (recurrent) policy. These extensions are especially interesting as they may allow more complicated curiosity-based or model-based algorithms to be learned. To this extent, it will be important to develop introspection methods that analyze the learned objective function and to scale MetaGenRL to make use of many more environments and agents.
Further reading
Have a look at the full paper on ArXiv.
I also recommend reading Jeff Clune’s AI-GAs. He describes a similar quest for Artifical Intelligence Generating Algorithms (AI-GAs) with three pillars:
- Meta-Learning algorithms
- Meta-Learning architectures
- Generating environments
Furthermore, there is a large body of work on meta-learning by my supervisor Juergen Schmidhuber (one good place to start is his first paper on Meta Learning for RL).
Please cite this work using
@inproceedings{
kirsch2020metagenrl,
title={Improving Generalization in Meta Reinforcement Learning using Learned Objectives},
author={Louis Kirsch and Sjoerd van Steenkiste and Juergen Schmidhuber},
booktitle={International Conference on Learning Representations},
year={2020}
}