NeurIPS 2018, Updates on the AI road map
In September, I published a technical report on what I consider the most important challenges in Artificial Intelligence. I categorized them into four areas
- Scalability
Neural networks where compute / memory cost does not scale quadratically / linearly with the number of neurons. - Continual Learning
Agents that have to continually learn from their environment without forgetting previously acquired skills and the ability to reset the environment. - Meta-Learning
Agents that are self-referential in order to modify their own learning algorithm. - Benchmarks
Environments that have complex enough structure and diversity such that intelligent agents can emerge without hardcoding strong inductive biases.
During the NeurIPS 2018 conference I investigated other researcher’s current approaches and perspectives on these issues.
Inductive biases?
I think it is interesting to point out that this list contains little discussion of particular inductive biases that solve challenges we observe with current reinforcement learning agents. Most of these challenges are absorbed into the Meta-Learning aspect of the system, similar to how evolution shaped a good learner. It remains to be seen how feasible this approach is with strongly limited compute and time constraints.
Scalability
It is almost obvious that if we seek to implement 100 billion neurons as found in the human brain using artificial neural networks (ANNs) that standard matrix-matrix multiplications will not take us very far. The number of required operations is quadratic in the number of neurons.
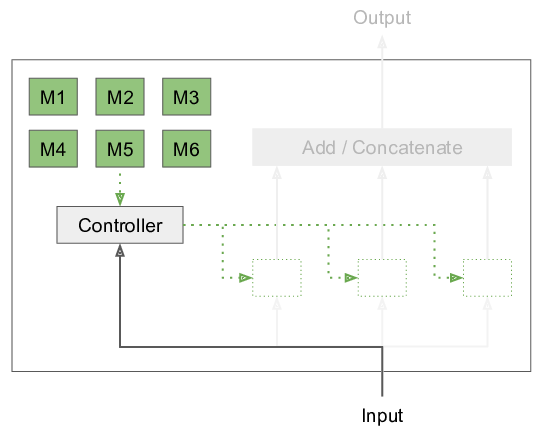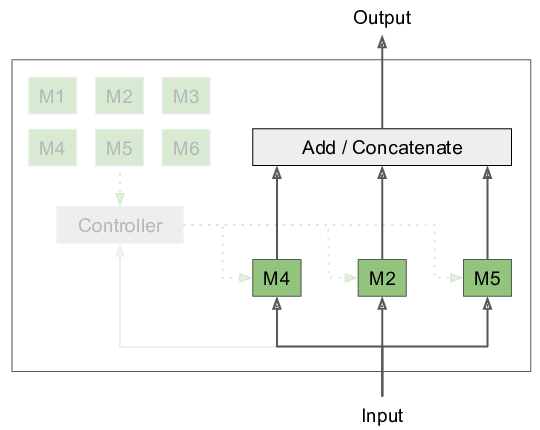
To address this issue, I have worked on and published Modular Networks at NeurIPS 2018. Instead of evaluating the entire ANN for each input element, we decompose the network into a set of modules, where only a subset is used depending on the input. This procedure is inspired by the human brain, where we can observe modularization that is also hypothesized to improve adaptation to changing environments and mitigate catastrophic forgetting. In our approach, we learn both the parameters of these modules, as well as the decision which modules to use jointly. Previous literature on conditional computation has had many issues with module collapse, i.e. the optimization process ignoring most of the available modules, leading to sub-optimal solutions. Our Expectation-Maximization based approach prevents these kinds of issues.
Unfortunately, forcing this kind of separation into modules has its own issues that we discussed in the paper and in this follow-up blog post on modular networks. Instead, we might seek to make use of sparsity and locality in weights and activations as discussed in my technical report on sparsity. In short, we only want to perform operations on the few activations that are non-zero, discarding entire rows in the weight matrix. If furthermore, connectivity is highly sparse, we in effect get rid of the quadratic cost down to a small constant. This kind of conditional computation and non-coalesced weight access is quite expensive to implement on current GPUs and usually not worth it.
NVIDIA’s take on conditional computation and sparsity
According to a software engineer and a manager at NVIDIA, there are no current plans to build hardware that can leverage conditional computation in the form of activation sparsity. The main reason seems to be the trade-off of generality vs speed. It is too expensive to build dedicated hardware for this use case because it might limit other (ML) applications. Instead, NVIDIA is more focused on weight sparsity from a software perspective at the moment. This weight sparsity also requires a high degree to be efficient.
GraphCore’s take on conditional computation and sparsity
GraphCore builds hardware that allows storing activations during the forward pass in caches close to the processing units instead of global memory on GPUs. It also can make use of sparsity and specific graph structure by compiling and setting up a computational graph on the device itself. Unfortunately, due to the expensive compilation, this structure is fixed and does not allow for conditional computation.
As an overall verdict, it seems that there is no hardware solution for conditional computation on the horizon and we have to stick with heavily parallelizing across machines for the moment. In that regard, Mesh-Tensorflow, a novel method to distribute gradient calculation not just across the batch but also across the model was published at NeurIPS, allowing even larger models to be trained in a distributed fashion.
Continual Learning
I have long advocated for the need for deep learning based continual learning systems, i.e. systems that can learn continually from experience and accumulate knowledge that can then be used as prior knowledge when new tasks arise. As such, they need to be capable of forward transfer, as well as preventing catastrophic forgetting. The Continual Learning workshop at NeurIPS discussed exactly these issues. Perhaps these two criteria are incomplete though, multiple speakers (Mark Ring, Raia Hadsell) suggested a larger list of requirements
- forward transfer
- backward transfer
- no catastrophic forgetting
- no catastrophic interference
- scalable (fixed memory / computation)
- can handle unlabeled task boundaries
- can handle drift
- no episodes
- no human control
- no repeatable states
In general, it seems to me that there are six categories of approaches to the problem
- (partial) replay buffer
- generative model that regenerates past experience
- slowing down training of important weights
- freezing weights
- redundancy (bigger networks -> scalability)
- conditional computation (-> scalability)
None of these approaches handle all aspects of the continual learning list. Unfortunately, this is also impossible in practice. There is always a trade-off between transfer and memory / compute, and a trade-off between catastrophic forgetting and transfer / memory / compute. Thus, it will be hard to purely quantitatively measure the success of an agent. Instead, we should build benchmarks that require qualities we require from our continual learning agents, for instance, the Starcraft based environment presented at the workshop.
Furthermore, Raia Hadsell argued that Continual Learning involves moving away from learning algorithms that rely on i.i.d. data to learning from a non-stationary distribution. In particular, humans are good at learning incrementally instead of iid. Thus, we might be able to unlock a more powerful ML paradigm when moving away from the iid requirement.
The paper Continual Learning by Maximizing Transfer and Minimizing Interference showed an interesting connection between REPTILE (a MAML successor) and reducing catastrophic forgetting. The dot product between gradients of datapoints (appears in REPTILE) that are drawn from a replay buffer leads to gradient updates that minimize interference and reduce catastrophic forgetting.
The panel with Marc’Aurelio Ranzato, Richard Sutton, Juergen Schmidhuber, Martha White, and Chelsea Finn was also quite interesting. It has been argued that we should experiment with lifelong learning in the control setting (if that is what we ultimately care about) instead of supervised and unsupervised learning to prevent any mismatch between algorithm development and actual area of application. Discount factors, while having useful properties for Bellman-equation based learning, might be problematic for more realistic RL settings. Returns with long time-horizons are what make humans inherently smarter than many other species. Furthermore, any learning, in particular meta-learning, is inherently constrained due to credit assignment. Thus, developing algorithms with cheap credit assignment are the key to intelligent agents.
Meta-Learning
Meta-Learning is about modifying the learning algorithm itself. This may be an outer optimization loop that modifies an inner optimization loop, or in its most universal form a self-referential algorithm that can modify itself. Many researchers are also concerned with fast adaptation, i.e. forward transfer, to new tasks / environments etc. This can be viewed as transfer learning, or meta-learning if we consider the initial parameters of a learning algorithm to be part of the learning algorithm. One of the very recent algorithms by Chelsea Finn, MAML, spiked great interest in this kind of fast adaptation algorithms. This could, for instance, be used for model-based reinforcement learning, where the model is quickly updated to changing dynamics.
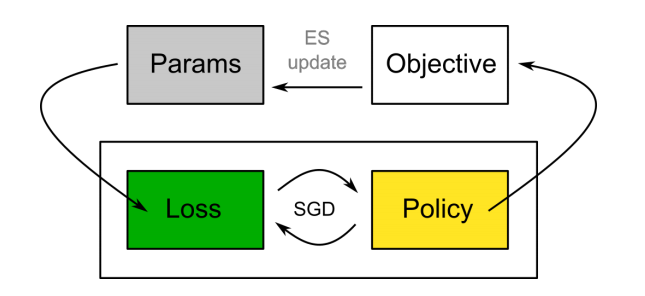
Another interesting idea is to learn differentiable loss functions of the agent’s trajectory and the policy output. This allows evolving the few parameters of the loss function while training the policy using SGD. Furthermore, the authors of Evolved Policy Gradients (EPG) showed that the learned loss functions generalize across reward functions and allow for fast adaptation. One major issue with EPG is that credit assignment is quite slow: An agent has to be fully trained using a loss function to obtain an average return (fitness) for the meta-learner.
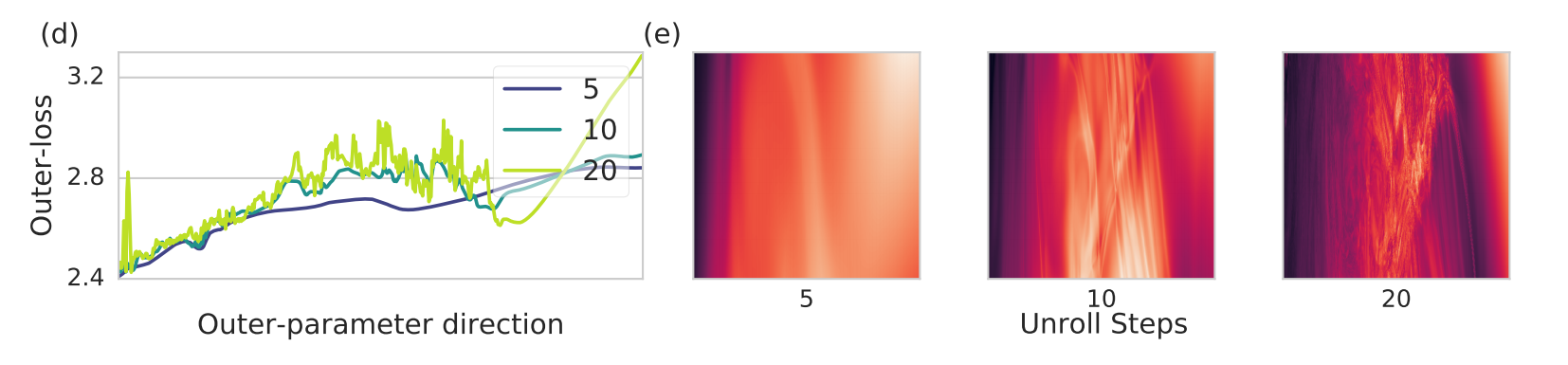
Left: one-dimensional. Right: two-dimensional. Taken from Metz et al
Another interesting discovery I made during the Meta-Learning workshop is the structure of loss landscapes of meta-learners. In a paper by Luke Metz on learning optimizers, he showed that the loss function of the optimizer parameters becomes more complex the more update steps are being unrolled. I suspect that this is a general behavior of meta-learning algorithms, small changes in parameter values can cascade to massive changes in the final performance. I would be very interested in such an analysis. In the case of learning optimization Luke addressed the issue by smoothing the loss landscape through Variational Optimization, a principled interpretation of evolutionary strategies.
Benchmarks
Most current RL algorithms are benchmarked on games or simulators such as ATARI or Mujoco. These are simple environments that have little resemblance of the richness our universe exhibits. One major complaint researchers often voice is that our algorithms are sample-inefficient. This can be fixed in part by using the existing data more efficiently through off-policy optimization and model-based RL. Though, a large factor is also that our algorithms have no prior experience to use in these benchmarks. We can get around this by handcrafting inductive biases into our algorithms that reflect some kind of prior knowledge but it might be much more interesting to build environments that allow the accumulation of knowledge that can be leveraged in the future. To my knowledge, no such benchmark exists to date. The Minecraft simulator might be closest to such requirements.
An alternative to such rich environments is to build explicit curriculums such as the beforementioned Starcraft environment that consists of a curriculum of tasks. This is in part also what Shagun Sodhani asks for in his paper Environments for Lifelong Reinforcement Learning. Other aspects he puts on his wishlist are
- environment diversity
- stochasticity
- naturality
- non-stationarity
- multiple modalities
- short-term and long-term goals
- multiple agents
- cause and effect interaction
The game engine developer Unity3D is also at the forefront of environment development. It has released a toolkit ML-Agents to train and evaluate agents in environments build with Unity. One of their new open-ended curriculum benchmarks is the Obstacle Tower. In general, a major problem for realistic environment construction is that the requirements are inherently different from game design: To prevent overfitting it is important that objects in a vast world do not look alike and as such can not just be replicated as it is often done in computer games. This means for true generalization we require generated or carefully designed environments.
Finally, I believe it might be possible to use computation to generate non-stationary environments instead of building them manually. For instance, this could be a physics simulator that has similar properties to our universe. To save compute, we could also start with a simplification based on voxels. If this simulation exhibits the right properties we might be able to simulate a process similar to evolution, bootstrapping a non-stationary environment that develops many forms of life that interact with each other. This idea fits nicely with the simulation hypothesis and has connections to Conway’s Game of Life. One major issue with this approach might be that the resulting complexity has no resemblance to human-known concepts. Furthermore, the resulting intelligent agents will not be able to transfer to our universe. Recently, I found out that this idea has been realized in part by Stanley and Clune’s group at UBER in their paper POET: Endlessly Generating Increasingly Complex and Diverse Learning Environments. The environment is non-stationary and can be viewed as an agent itself that maximizes complexity and agent learning progress. They refer to this concept as open-ended learning, and I recommend reading this article.
Please cite this work using
@misc{kirsch2019roadmap,
author = {Kirsch, Louis},
title = {{Updates on the AI road map}},
url = {http://louiskirsch.com/neurips-2018},
year = {2019}
}